¿QUÉ ES EL PROMPT?
Se llama prompt al carácter o conjunto de caracteres que se muestran en una línea de comandos para indicar que está a la espera de órdenes. Éste puede variar dependiendo del intérprete de comandos y suele ser configurable.
DEBUG
 |
| Nota: "Bug" significa fallo, defecto en un programa; "debug" significa depurar (escrutar y eliminar fallos). La palabra ha quedado como verbo (depurar), de la que han derivado otras. Por ejemplo: "Debugger" (depurador). Por extensión, todos los programas y utilidades que sirven para escudriñar los datos y el código a bajo nivel, se identifican genéricamente con esta denominación. |
DEBUG.EXE es un ejecutable que, hasta 2001, acompañó a todas las versiones de MS-DOS, a partir de la 2.0, y de Windows [1]. Es sin duda un programa antiguo pero de enorme potencial didáctico para el principiante. En adelante nos referiremos a él como debug simplemente.
He aqui algunas funcionalidades para entender mejor
Comando TREE:
Presenta en forma gráfica la estructura de directorios de una ruta de acceso o del disquete en una unidad de disco.
Sintaxis:
TREE [unidad:] [ruta] [/F] [/A]
Parámetros:
unidad:
Especifica la unidad de disco que contiene el disquete cuya estructura de directorios desee presentar.
ruta:
Especifica el directorio cuya estructura de directorios desee presentar.
Modificador
/F
Presenta los nombres de los archivos que contiene cada directorio.
/A
Indica al comando TREE que utilice caracteres de texto en lugar de caracteres gráficos para mostrar las líneas que vinculan los subdirectorios. Utilice este modificador con tablas de códigos que no reconozcan caracteres gráficos y para enviar información a impresoras que no los puedan interpretar adecuadamente.
A continuación veremos la creación de directorios a partir de este comando.
ASEMBLER DEBUG
Otras utilidades del debug
AX: Acumulador (AL:AH)
BX: Registro base (BL:BH)
Modos de direccionamiento
Son medios que facilitan la tarea de programación, permitiendo el acceso a los datos
de una manera natural y eficiente.
Estos indican al procesador como calcular la dirección absoluta (real o efectiva) donde
se encuentran los datos.
1.- Direccionamiento de Registro: Los operandos o datos se encuentran en registros
No se necesita calcular la Dir. Absoluta.
P.e.
ADD BX, CX
MOV BX, AX
SUB DX, BX
2.- Direccionamiento inmediato : El operando es un número que forma parte de la
instrucción. No se necesita calcular la dir absoluta.
P.C.
ADD BX, 2h
SUB CX, 100h
MOV dx, 30h.
3.- Modo directo: La dirección del operando viene incluida en la instrucción , aquí el
procesador calcula la dirección real ([DS]+Dir)
TOP
A la hora de realizar el mantenimiento y monitorización de un servidor GNU/Linux (o de nuestro propio ordenador) hay comandos que son de gran ayuda e importancia. El comando top nos ayuda a conocer los procesos de ejecución del sistema (y más cosas) en tiempo real y es una de las herramientas más importantes para un administrador.
Ejecutar el comando
Abrimos una consola y simplemente ejecutamos el comando:
Nos va a aparecer una interfaz en modo texto que se va a ir actualizando cada 3 segundos. Muestra un resumen del estado de nuestro sistema y la lista de procesos que se están ejecutando. La salida que obtengo en mi ordenador es la siguiente:
1. Tiempo de actividad y carga media del sistema

En la primera línea nos muestra:
Hora actual.
Tiempo que ha estado el sistema encendido.
Número de usuarios (mario y root).
Carga media en intervalos de 5, 10 y 15 minutos respectivamente.
2. Tareas
La segunda línea muestra el total de tareas y procesos, los cuales pueden estar en diferentes estados. Yo lo tengo en castellano y la traducción es un poco pobre, así que lo explico en inglés:
Running (ejecutar): procesos ejecutándose actualmente o preparados para ejecutarse.
Sleeping (hibernar): procesos dormidos esperando que ocurra algo (depende del proceso) para ejecutarse.
Stopped (detener): ejecución de proceso detenida.
Zombie: el proceso no está siendo ejecutado. Estos procesos se quedan en este estado cuando el proceso que los ha iniciado muere (padre).
3. Estados de la CPU
Esta línea nos muestra los porcentajes de uso del procesador diferenciado por el uso que se le de.
us (usuario): tiempo de CPU de usuario.
sy (sistema): tiempo de CPU del kernel.
id (inactivo): tiempo de CPU en procesos inactivos.
wa (en espera): tiempo de CPU en procesos en espera.
hi (interrupciones de hardware): interrupciones de hardware.
si (interrupciones de software): tiempo de CPU en interrupciones de software.
6. Columnas
Ahora vamos a ver las diferentes columnas que nos encontramos al ejecutar el comando.
PID: es el identificador de proceso. Cada proceso tiene un identificador único.
USER (USUARIO): usuario propietario del proceso.
PR: prioridad del proceso. Si pone RT es que se está ejecutando en tiempo real.
NI: asigna la prioridad. Si tiene un valor bajo (hasta -20) quiere decir que tiene más prioridad que otro con valor alto (hasta 19).
VIRT: cantidad de memoria virtual utilizada por el proceso.
RES: cantidad de memoria RAM física que utiliza el proceso.
SHR: memoria compartida.
S (ESTADO): estado del proceso.
%CPU: porcentaje de CPU utilizado desde la última actualización.
%MEM: porcentaje de memoria física utilizada por el proceso desde la última actualización.
TIME+ (HORA+): tiempo total de CPU que ha usado el proceso desde su inicio.
COMMAND: comando utilizado para iniciar el proceso.




















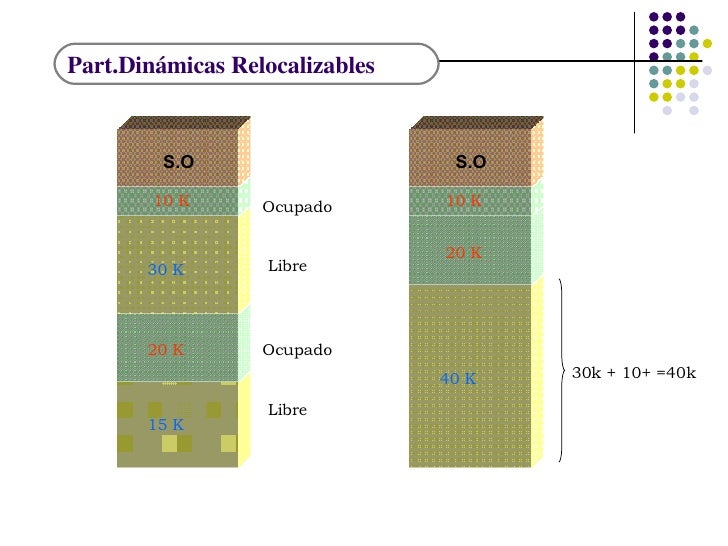


















 Planificación CPU basada en colas multinivel
Planificación CPU basada en colas multinivel
